Optimizing like mad

Written by Pascal Touset on 11th May 2015
Finding my book back
A long time ago, I returned a book ‘MySQL for Dummies’ to the library. Later, I remembered I made important notes on the last page. So I went back to the library to find the book. I opened each and every book in the library to look for notes. Then, I checked if one of those books was titled ‘MySQL for Dummies’. I found one – with my notes. It took forever.
Yes, this story is wrong on many levels. One of them is how much faster it is to only look in the ‘MySQL for Dummies’ books. But this illustrates what MySQL did in our new fraud detection system on the VoIPGRID platform. This article describes what happened and how we found a solution.
Detecting fraud
First, a bit of background information about our fraud detection system. This system detects suspicious calling behaviour, for instance when one of our clients has a sudden increase in call traffic to potentially fraudulent destinations. This can happen when their VoIP trunk is hacked by an outsider. Once detected by us, their call traffic is blocked and the client is protected from running into sky-high costs – often, these costs now stay below 1 euro.
The detection is done by analyzing the traffic data of a set of clients over a certain timespan. The traffic data is stored in two large tables:
- Call, which represents a single call, containing general data such as the client.
- Participant, which represents a call part, containing detailed data such as the dialed number and the date and time of hangup.
A Call has one or more Participants. We need a set of Participants to do analysis on. In Django, this can be done with a simple lookup. For example, if we need the traffic data of calls which ended between 1pm and 2pm on May 1st for clients with client codes 12345 and 12346, we can run this code:
Participant.objects.filter(
hangup__range=[datetime(2015, 5, 1, 13, 0, 0), datetime(2015, 5, 1, 14, 0, 0)],
call__clientcode__in=(12345, 12346)),
)
Under the hood, Django generates a MySQL query for it:
SELECT *
FROM `call_participant`
INNER JOIN `call_call`
ON `call_participant`.`linkedid` = `call_call`.`linkedid`
WHERE `call_participant`.`hangup` BETWEEN "2015-05-01 13:00:00" and "2015-05-01 14:00:00"
AND `call_call`.`clientcode` IN (12345, 12346);
MySQL executes the query, Django creates a QuerySet from the result, and we are done. Except we are not.
Where it went haywire
99% of the time, the QuerySet is created in a split of a second – no problem there. The other 1% however, it seemed to just hang for about a minute.
At first, we were clueless why, but soon the MySQL optimizer was our prime suspect. So we dug into the MySQL queries outputted by Django, and on how MySQL executes these queries using explain.
Now, in the WHERE clause of the MySQL query above, we see two columns: hangup and clientcode. Both columns are indexed. However, the use of the index on the hangup column is much faster in this query. Thus, the order in which the indexes are used by MySQL matters. As it turned out, 99% of the time, the MySQL optimizer chooses to use index on hangup first. But, once in a while, it goes ape shit mad and chooses to use the index on clientcode first.
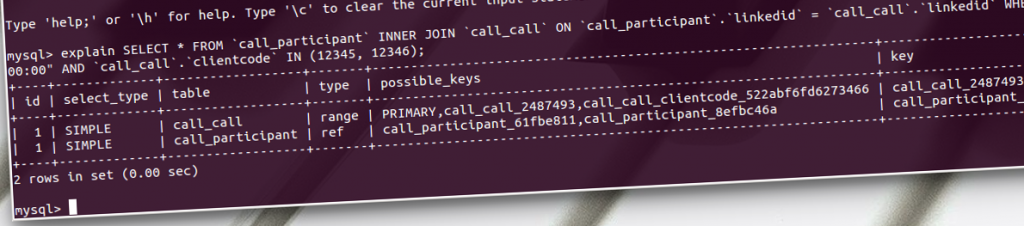
In other words, it looks at every book in the library with notes on the last page, instead of just those called ‘MySQL for Dummies’. That explains why these queries take so long.
Where we found peace
We had to force MySQL to use the index on hangup before using the index on clientcode. In MySQL, using an index can be forced with the USE INDEX clause. However, Django supports no way to force the use of an index. We had to omit the ORM.
So, first we fetch the primary keys of Participants with a MySQL query:
cursor.execute('''
SELECT `call_participant`.`uniqueid`
FROM `call_participant`
USE INDEX (`call_participant_8efbc46a`)
INNER JOIN `call_call`
ON `call_participant`.`linkedid` = `call_call`.`linkedid`
WHERE `call_participant`.`hangup` BETWEEN "2015-05-01 13:00:00" and "2015-05-01 14:00:00"
AND `call_call`.`clientcode` IN (12345, 12346);
''')
New in this query is the clause USE INDEX (`call_participant_8efbc46a`). This makes sure that the index on hangup is used first, instead of the index on clientcode. In our case, call_participant_8efbc46a is always the key_name of the index on hangup – every time that index is created, this exact key_name is generated.
We then use the result of the query to create a QuerySet, like so:
Participant.objects.filter(uniqueid__in=[pks[0] for pks in cursor.fetchall()])
We can use this QuerySet in the fraud detection system for our traffic data analysis. The sole purpose of all this is forcing MySQL to use one index before another. If that was not necessary, Django’s ORM would have been good enough.
The lesson for us was: if you stumble upon inconsistent performance issues, it may be the MySQL optimizer, optimizing like mad, checking out every book in the library.

Your thoughts
Written by Adam Johnson on 17th June 2015
Neat. The ORM does indeed need obviating sometimes.
I’m planning at some point in making a MySQL index hint extension to the ORM as part of my library django-mysql. It already supports the select hints like STRAIGHT_JOIN and I just need to extend that. The Github issue is here if you want to follow: https://github.com/adamchainz/django-mysql/issues/131
Written by Pascal Touset on 17th June 2015
Hi Adam, thanks for your comment. It is awesome to see that you plan on working on this. I am following!